Generative Adversarial Networks (GANs)
Generative Adversarial Networks are used to generate images that never existed before. They learn about the world (objects, animals and so forth) and create new versions of those images that never existed. In this tutorial, we will go through the basics of GANs




- Introduction
- Generative Adversarial Networks (GANs)
- How GANs Work
- GANs Process
- Examples
- Generating Hand-Written digits
- MNIST Dataset
- Discriminator vs. Generator
Introduction
- Generative Adversarial Networks (GANs)
- How GANs Work
- GANs Process
- Examples
- Generating Hand-Written digits
Generative Adversarial Networks (GANs)
Generative Adversarial Networks are used to generate images that never existed before. They learn about the world (objects, animals and so forth) and create new versions of those images that never existed.
They have two components:
- A Generator - this creates the images.
- A Discriminator - this assesses the images and tells the generator if they are similar to what it has been trained on. These are based off real world examples.
When training the network, both the generator and discriminator start from scratch and learn together.
How GANs Work
G for Generative - this is a model that takes an input as a random noise singal and then outputs an image.
A for Adversarial - this is the discriminator, the opponent of the generator. This is capable of learning about objects, animals or other features specified. For example: if you supply it with pictures of dogs and non-dogs, it would be able to identify the difference between the two.
Using this example, once the discriminator has been trained, showing the discriminator a picture that isn't a dog it will return a 0. Whereas, if you show it a dog it will return a 1.
N for Network - meaning the generator and discriminator are both neural networks.
GANs Process
Step 1 - we input a random noise signal into the generator. The generator creates some images which is used for training the discriminator. We provide the discriminator with some features/images we want it to learn and the discriminator outputs probabilities. These probabilities can be rather high as the discriminator has only just started being trained. The values are then assessed and identified. The error is calculated and these are backpropagated through the discriminator, where the weights are updated.
Next we train the generator. We take the batch of images that it created and put them through the discriminator again. We do not include the feature images. The generator learns by tricking the discriminator into it outputting false positives.
The discriminator will provide an output of probabilities. The values are then assessed and compared to what they should have been. The error is calculated and backpropagated through the generator and the weights are updated.
Step 2 - This is the same as step 1 but the generator and discriminator are trained a little more. Through backpropagation the generator understands its mistakes and starts to make them more like the feature.
This is created through a Deconvolutional Neural Network.
Examples
GANs can be used for the following:
- Generating Images
- Image Modification
- Super Resolution
- Assisting Artists
- Photo-Realistic Images
- Speech Generation
- Face Ageing
It’s Training Cats and Dogs: NVIDIA Research Uses AI to Turn Cats Into Dogs, Lions and Tigers, Too


Generating Hand-Written digits
Let's strat by importing some useful packages
import torch
from torch import nn
from tqdm.auto import tqdm
from torchvision import transforms
from torchvision.datasets import MNIST # Training dataset
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
torch.manual_seed(0) # Fixing Seed for Reproducibility
import warnings
warnings.filterwarnings('ignore')
Let's create a visualizer function to see the input and output data.
def show_tensor_images(image_tensor, num_images=25, size=(1, 28, 28)):
'''
Function for visualizing images: Given a tensor of images, number of images, and
size per image, plots and prints the images in a uniform grid.
'''
image_unflat = image_tensor.detach().cpu().view(-1, *size)
image_grid = make_grid(image_unflat[:num_images], nrow=5)
plt.imshow(image_grid.permute(1, 2, 0).squeeze())
plt.show()
MNIST Dataset
The training images your discriminator will be using is from a dataset called MNIST. It contains 60,000 images of handwritten digits, from 0 to 9, like these:

Discriminator vs. Generator
The first thing that we will get to explore is the difference between a discriminator and a generator. Remember that these are the two main components of a GAN!
What is a discriminator?
One of the most widely used type of ML models is the classifier, which is used to sift through items in a dataset and classify them into different categories. For example, you might be familiar with image classifiers that discriminate between images of a cat and images of a dog. For a well-trained classifier: when you give it an image of a cat, it will say "cat"! When you give it an image of a dog, it will say "dog"! You can also use other classes, like coconuts vs. starfruit.

Image Credit:Google In terms of probabilities, the classifier wants to find $p(y|x)$: the probability that given an image input $x$, the image class $y$ is cat, $p(y=\text{cat}|x)$, or dog, $p(y=\text{dog}|x)$.
The discriminator is simply a classifier with two classes: real and fake. Given an input x, the discriminator will calculate the probabilities $p(y=\text{real}|x)$ and $p(y=\text{fake}|x)$ and classify $x$. The input $x$ can be anything that you have the generator create and is not limited to images. Your GAN can be trained on videos, text, audio, etc.
What is a generator?
Generators are designed to have a different goal from discriminators (classifiers). Imagine you're working at a tropical fruit stand and asked to sort the fruit into two categories: coconuts and starfruit. That's the job of a classifier. But what if a customer comes up to the stand, and asks: what is a starfruit? You can't just say that it's not a coconut. You would need to explain what makes something a starfruit and what doesn't, not just its differences from a coconut. That's the job of a generator: to represent different classes in general, not just distinguish them.
In terms of probabilities, the generator wants to figure out $p(x|y)$: the probability that, given that you generated a starfruit $(y=\text{starfruit})$, the resulting image $(x)$ is the one generated. The output space of possible starfruit images is huge, so that makes this challenging for the generator.
This can be a much harder task than discrimination. Typically, you will need the generator to take multiple steps to improve itself for every step the discriminator takes. It's easy to tell the difference between a coconut and a starfruit when you look at a mix of them, but to know exactly all the features of all possible coconuts in the world? That's a lot, but it's really cool if you can get even close to it, because you can start generating all sorts of coconuts and starfruit when you do. I don't have a generator for these tropical fruits figured out for you to play with, but you can generate all kinds of cool things with these models, like realistic faces!
In the below image, the generator is trying to find the features that represent all cats using the feedback from the discriminator.
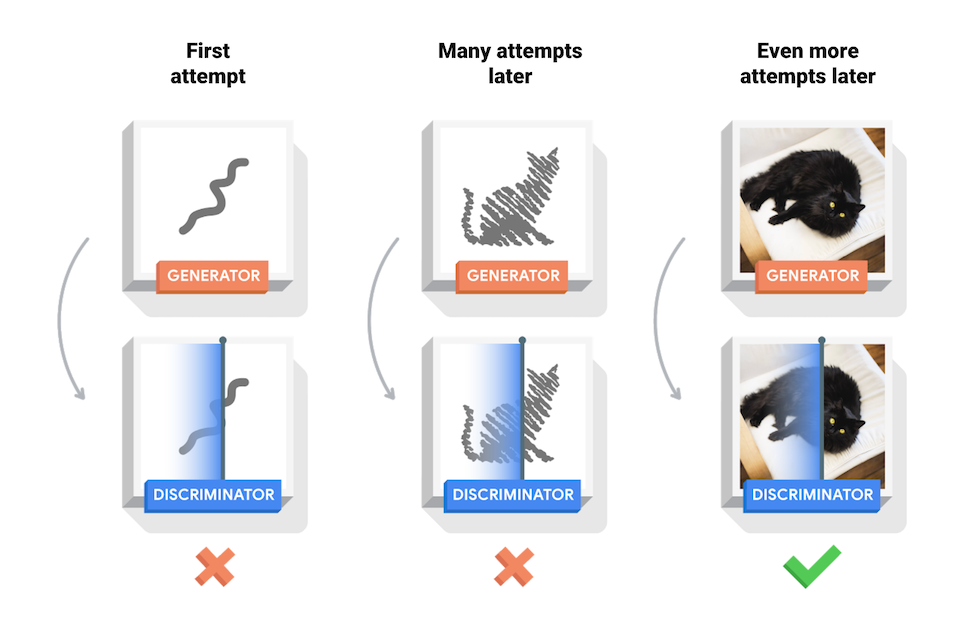
Image Credit:TensorFlow
Generator
The first step is to build the generator component.
We will start by creating a function to make a single layer/block for the generator's neural network. Each block should include a linear transformation to map to another shape, a batch normalization for stabilization, and finally a non-linear activation function (ReLU) so the output can be transformed in complex ways.
def generator_block(input_dim, output_dim):
'''
Function for returning a block of the generator's neural network
given input and output dimensions.
Parameters:
input_dim: the dimension of the input vector, a scalar
output_dim: the dimension of the output vector, a scalar
Returns:
a generator neural network layer, with a linear transformation
followed by a batch normalization and then a relu activation
'''
return nn.Sequential(
# Linear Transformation Layer
nn.Linear(input_dim, output_dim),
# BatchNorm1d for stablizing the training process
nn.BatchNorm1d(output_dim),
# Add some non-linearity effect
nn.ReLU(inplace=True)
)
Now, we can build the generator class. It will take 3 values:
- The noise vector dimension
- The image dimension
- The initial hidden dimension
Using these values, the generator will build a neural network with 5 layers/blocks. Beginning with the noise vector, the generator will apply non-linear transformations via the block function until the tensor is mapped to the size of the image to be outputted (the same size as the real images from MNIST). The final layer does not need a normalization or activation function, but does need to be scaled with a sigmoid function.
Finally, you are given a forward pass function that takes in a noise vector and generates an image of the output dimension using your neural network.
class Generator(nn.Module):
'''
Generator Class
Values:
z_dim: the dimension of the noise vector, a scalar
im_dim: the dimension of the images, fitted for the dataset used, a scalar
(MNIST images are 28 x 28 = 784 so that is your default)
hidden_dim: the inner dimension, a scalar
'''
def __init__(self, z_dim=10, im_dim=784, hidden_dim=128):
super(Generator, self).__init__()
# Building a Generator Neural Network
# 6 - Generator Blocks (Previously Built)
self.gen = nn.Sequential(
generator_block(z_dim, hidden_dim),
generator_block(hidden_dim, hidden_dim * 2),
generator_block(hidden_dim * 2, hidden_dim * 4),
generator_block(hidden_dim * 4, hidden_dim * 8),
generator_block(hidden_dim * 8, hidden_dim * 16),
generator_block(hidden_dim * 16, hidden_dim * 8),
# Ouptput Layer = Linear Transformation + Sigmoid activation
nn.Linear(hidden_dim * 8, im_dim),
nn.Sigmoid()
)
def forward(self, noise):
'''
Function for completing a forward pass of the generator: Given a noise tensor,
returns generated images.
Parameters:
noise: a noise tensor with dimensions (n_samples, z_dim)
'''
return self.gen(noise)
Noise
In order to use your generator, you will need to be able to create noise vectors. The noise vector z has the important role of making sure the images generated from the same class don't all look the same -- It's like a random seed. We will generate it randomly using PyTorch by sampling random numbers from the normal distribution. Since multiple images will be processed per pass, we will generate all the noise vectors at once.
def get_noise(n_samples, z_dim, device='cuda'):
'''
Function for creating noise vectors: Given the dimensions (n_samples, z_dim),
creates a tensor of that shape filled with random numbers from the normal distribution.
Parameters:
n_samples: the number of samples to generate, a scalar
z_dim: the dimension of the noise vector, a scalar
device: the device type
'''
return torch.randn((n_samples, z_dim), device=device)
def discriminator_block(input_dim, output_dim):
'''
Discriminator Block
Function for returning a neural network of the discriminator given input and output dimensions.
Parameters:
input_dim: the dimension of the input vector, a scalar
output_dim: the dimension of the output vector, a scalar
Returns:
a discriminator neural network layer, with a linear transformation
followed by an nn.LeakyReLU activation with negative slope of 0.2
(https://pytorch.org/docs/master/generated/torch.nn.LeakyReLU.html)
'''
return nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.LeakyReLU(negative_slope=0.2, inplace=True)
)
Now we can use these blocks to make a discriminator! The discriminator class holds 2 values:
- The image dimension
- The hidden dimension
The discriminator will build a neural network with 4 layers. It will start with the image tensor and transform it until it returns a single number (1-dimension tensor) output. This output classifies whether an image is fake or real. Note that you do not need a sigmoid after the output layer since it is included in the loss function. Finally, to use your discrimator's neural network you are given a forward pass function that takes in an image tensor to be classified.
class Discriminator(nn.Module):
'''
Discriminator Class
Values:
im_dim: the dimension of the images, fitted for the dataset used, a scalar
(MNIST images are 28x28 = 784 so that is your default)
hidden_dim: the inner dimension, a scalar
'''
def __init__(self, im_dim=784, hidden_dim=128):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
# 3 - Discriminator Blocks
discriminator_block(im_dim, hidden_dim * 4),
discriminator_block(hidden_dim * 4, hidden_dim * 8),
discriminator_block(hidden_dim * 8, hidden_dim * 4),
discriminator_block(hidden_dim * 4, hidden_dim * 2),
discriminator_block(hidden_dim * 2, hidden_dim),
# Adding a linear output
nn.Linear(hidden_dim , 1)
)
def forward(self, image):
'''
Function for completing a forward pass of the discriminator: Given an image tensor,
returns a 1-dimension tensor representing fake/real.
Parameters:
image: a flattened image tensor with dimension (im_dim)
'''
return self.disc(image)
Training
First, we will set your parameters:
- criterion: the loss function
- n_epochs: the number of times you iterate through the entire dataset when training
- z_dim: the dimension of the noise vector
- display_step: how often to display/visualize the images
- batch_size: the number of images per forward/backward pass
- lr: the learning rate
- device: the device type, here using a GPU (which runs CUDA), not CPU
Next, we will load the MNIST dataset as tensors using a dataloader.
criterion = nn.BCEWithLogitsLoss()
n_epochs = 500
z_dim = 64
display_step = 10000
batch_size = 64
lr = 0.00001
# Load MNIST dataset as tensors
dataloader = DataLoader(
MNIST('.', download=True, transform=transforms.ToTensor()),
batch_size=batch_size,
shuffle=True)
### Set the device for training
device = 'cuda'
Now, we can initialize the generator, discriminator, and optimizers. Note that each optimizer only takes the parameters of one particular model, since we want each optimizer to optimize only one of the models.
gen = Generator(z_dim).to(device)
gen_opt = torch.optim.Adam(gen.parameters(), lr=lr)
disc = Discriminator().to(device)
disc_opt = torch.optim.Adam(disc.parameters(), lr=lr)
Before we train our GAN network, we will need to create functions to calculate the discriminator's loss and the generator's loss. This is how the discriminator and generator will know how they are doing and improve themselves.
def get_disc_loss(gen, disc, criterion, real, num_images, z_dim, device):
'''
Return the loss of the discriminator given inputs.
Parameters:
gen: the generator model, which returns an image given z-dimensional noise
disc: the discriminator model, which returns a single-dimensional prediction of real/fake
criterion: the loss function, which should be used to compare
the discriminator's predictions to the ground truth reality of the images
(e.g. fake = 0, real = 1)
real: a batch of real images
num_images: the number of images the generator should produce,
which is also the length of the real images
z_dim: the dimension of the noise vector, a scalar
device: the device type
Returns:
disc_loss: a torch scalar loss value for the current batch
'''
# Create noise vectors and generate a batch (num_images) of fake images.
z_noise = get_noise(num_images, z_dim, device)
fake_imgs = gen(z_noise)
# Get the discriminator's prediction of the fake image and calculate the loss
disc_fake_pred = disc(fake_imgs.detach())
disc_fake_loss = criterion(disc_fake_pred, torch.zeros_like(disc_fake_pred))
# Get the discriminator's prediction of the real image and calculate the loss.
disc_real_pred = disc(real)
disc_real_loss = criterion(disc_real_pred, torch.ones_like(disc_real_pred))
# Calculate the discriminator's loss by averaging the real and fake loss
disc_loss = (disc_real_loss + disc_fake_loss)/2
return disc_loss
def get_gen_loss(gen, disc, criterion, num_images, z_dim, device):
'''
Return the loss of the generator given inputs.
Parameters:
gen: the generator model, which returns an image given z-dimensional noise
disc: the discriminator model, which returns a single-dimensional prediction of real/fake
criterion: the loss function, which should be used to compare
the discriminator's predictions to the ground truth reality of the images
(e.g. fake = 0, real = 1)
num_images: the number of images the generator should produce,
which is also the length of the real images
z_dim: the dimension of the noise vector, a scalar
device: the device type
Returns:
gen_loss: a torch scalar loss value for the current batch
'''
# Create noise vectors and generate a batch of fake images.
z_noise = get_noise(num_images, z_dim, device)
fake_imgs = gen(z_noise)
# Get the discriminator's prediction of the fake image.
disc_fake_pred = disc(fake_imgs)
# Calculate the generator's loss (Note: It compares the generator output of fake images with the real ones)
gen_loss = criterion(disc_fake_pred, torch.ones_like(disc_fake_pred))
return gen_loss
cur_step = 0
mean_generator_loss = 0
mean_discriminator_loss = 0
test_generator = True # Whether the generator should be tested
gen_loss = False
error = False
for epoch in range(n_epochs):
# Dataloader returns the batches
for real, _ in tqdm(dataloader):
cur_batch_size = len(real)
# Flatten the batch of real images from the dataset
real = real.view(cur_batch_size, -1).to(device)
### Update discriminator ###
# Zero out the gradients before backpropagation
disc_opt.zero_grad()
# Calculate discriminator loss
disc_loss = get_disc_loss(gen, disc, criterion, real, cur_batch_size, z_dim, device)
# Update gradients
disc_loss.backward(retain_graph=True)
# Update optimizer
disc_opt.step()
# For testing purposes, to keep track of the generator weights
if test_generator:
old_generator_weights = gen.gen[0][0].weight.detach().clone()
gen_opt.zero_grad()
gen_loss = get_gen_loss(gen, disc, criterion, cur_batch_size, z_dim, device)
gen_loss.backward()
gen_opt.step()
# For testing purposes, to check that your code changes the generator weights
if test_generator:
try:
assert lr > 0.0000002 or (gen.gen[0][0].weight.grad.abs().max() < 0.0005 and epoch == 0)
assert torch.any(gen.gen[0][0].weight.detach().clone() != old_generator_weights)
except:
error = True
print("Runtime tests have failed")
# Keep track of the average discriminator loss
mean_discriminator_loss += disc_loss.item() / display_step
# Keep track of the average generator loss
mean_generator_loss += gen_loss.item() / display_step
### Visualization code ###
if cur_step % display_step == 0 and cur_step > 0:
print(f"Epoch {epoch}, step {cur_step}: Generator loss: {mean_generator_loss}, discriminator loss: {mean_discriminator_loss}")
fake_noise = get_noise(cur_batch_size, z_dim, device=device)
fake = gen(fake_noise)
show_tensor_images(fake)
show_tensor_images(real)
mean_generator_loss = 0
mean_discriminator_loss = 0
cur_step += 1



























































































